TL;DR
- 本文解決:Claude Code 用了半年,memory 越存越多卻越記越亂的問題
- 推薦給:有在用 Claude Code、CLAUDE.md、auto memory,但發現「跟它講過的事它常常還是不記得」的人
- 讀完你會知道:為什麼 50 個 memory 檔反而等於沒記憶、Obsidian Graph View 怎麼當你的 AI 大腦健檢工具、整理之後我做了哪三件事讓它從花朵變星雲
我用 Claude Code 用了半年。memory 從一開始的 10 個檔,長到 51 個全局檔 + 25 個專案級檔。每次踩到坑,我就喊 Claude「記下來」,它就乖乖開個 feedback_xxx.md 寫進去。
直到 2026 年 5 月 21 日,我用 Obsidian Graph View 打開 ~/.claude/memory/,看到一個讓我尷尬的畫面 — 所有 memory 檔,只跟中心的 MEMORY.md 連著,檔跟檔之間幾乎沒有任何連線。
我以為我在養一個 AI 大腦。實際我在養一個爛筆記資料夾。
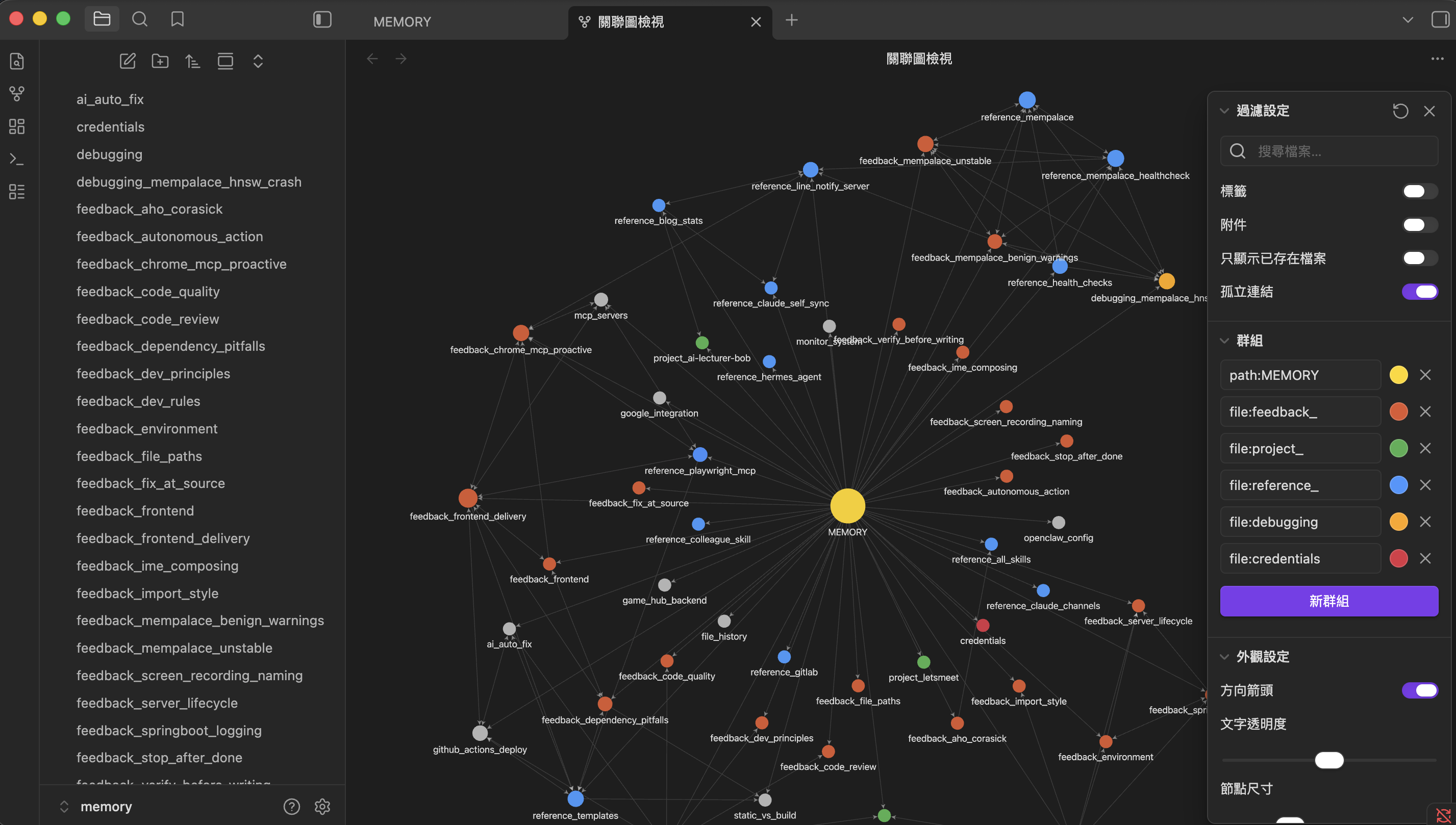
這篇是 Memory 治理系列三篇的第一篇,先把問題講清楚:為什麼會這樣、誰該負責、要怎麼修。下兩篇會拆「規則為什麼這樣寫」(EP2)跟「Obsidian 怎麼當大腦健檢工具」(EP3)。
📌 目錄
🧠 Claude Code memory 是什麼
先講概念,不然後面看不懂。
Claude Code 有兩套「記憶」系統,常被混在一起講,其實是兩件事:
| 系統 | 觸發方式 | 檔案位置 | 用途 |
|---|---|---|---|
| CLAUDE.md | 每次 session 開始全文載入 | 專案根 ./CLAUDE.md + 全域 ~/.claude/CLAUDE.md | 你主動寫給 Claude 看的指令、規範、紀律 |
| auto memory | 你叫 Claude「記下來」/ Claude 自己判斷該記 | ~/.claude/memory/*.md + ~/.claude/projects/ | Claude 自動累積的踩坑、偏好、專案脈絡 |
社群最佳實踐是 CLAUDE.md 控制在 80-120 行內,讓它高訊號、低噪音;深的、會變的、踩坑型的東西丟給 auto memory 去長。
聽起來很合理對吧?問題是 — auto memory 自己長,不代表會長得健康。
🌸 我的爛筆記到底有多爛
整理當天我把 ~/.claude/memory/ 跟 ~/.claude/projects/-Users-yanchen/memory/ 兩個資料夾打開,做了 diff:
| 指標 | 整理前 |
|---|---|
| 全局 memory 檔數 | 51 |
| 專案級 memory 檔數 | 25 |
| 兩邊同名重複的檔 | 9 個 |
| Obsidian Graph 連線數 | ~30 條(幾乎全是 MEMORY.md → 子檔) |
| 平均每檔 cross-link 數 | 0.6 |
| 檔名 | 內容 |
|---|---|
feedback_code_quality.md | Code Review 清單(設計/安全/異常/可讀性/測試/效能/死代碼)+ Java import 風格 |
feedback_code_review.md | Code Review 清單(同樣 7 大類,文字略改但項目一致)+ 工具建議 |
feedback_dev_principles.md | 開發原則(TDD + 程式碼品質 + 測試覆蓋率) |
Claude 真的需要回憶「我們對 code review 的標準」時,它讀的是哪一個?答案是 — 都不會讀,因為它根本不知道這三個並存。
memory 多 ≠ 記憶好。50 個沒連結的孤兒檔,在 Claude 眼裡跟 0 個 memory 沒太大差別 — 它每次回憶得從頭讀所有檔,而上下文有限。
🔍 三個結構性根因
整理完之後我寫了一份反思,放在 ~/.claude/memory/_reflection_2026-05-21.md。三個根因:
根因 1:同主題開新檔,不擴充既有檔
CLAUDE.md 我寫過「不要寫重複的記憶,先檢查現有的」這條規則,但沒有強制執行機制。每次 user 講「以後 code review 都要做這幾項」,Claude 直覺反應是「開個 feedback_code_review.md」 — 而不是先 ls ~/.claude/memory/feedback_*.md。規則沒給判準 + 沒主動查既有 = 雙重失誤。
根因 2:寫的時候沒加 [[link]]
抽查 5 個檔,只有 1 個有完整 cross-link。CLAUDE.md 寫的是「可以」用 [[name]] 連到相關 memory,不是「必須」。實際寫的時候,Claude 專心在「把這次對話濃縮成一個檔」,沒有「寫完問自己:這個檔跟哪些既有檔相關?」這個 checkpoint。沒有強制 checkpoint → 永遠不做。
根因 3:全局 vs 專案級邊界模糊
全局有 feedback_aho_corasick.md,專案級也有。但 aho-corasick 是跨專案行為規範,只應該存在全局。原因:Claude Code 早期 auto memory 預設寫到「專案級」(根據 cwd 自動判定),某個時間點改了規則開始寫到全局,但沒人清舊的 → 並存。規則沒判準 + 沒清理機制 → 自然漂移。
三個根因的共通模式:CLAUDE.md 的 auto-memory 規則是「描述性」的(寫什麼類型該存),不是「程序性」的(寫之前先做什麼、寫完之後檢查什麼)。描述性規則 LLM 跟人類一樣會「同意但忘記」。程序性 SOP 才會「被迫執行」。
「描述性 vs 程序性」這個對立不是 prompt engineering 的固定學術術語,是我整理完 CLAUDE.md 之後自己歸納的對應。學術上比較接近的概念是 Chain-of-Thought 之類的程序化 prompting,但語境跟「規則設計」不完全一樣。
🛠️ 整理之後做了哪三件事
1. 合併三胞胎 + 全檔補 cross-link
feedback_code_review.md 留下當入口(最新、最完整),其他兩個改成 .archived.md 後綴(不刪、留歷史)。每份 memory 結尾補上 ## 相關 區塊,用 wiki-link 指向同 cluster 的兄弟檔。26 個檔都補完,cross-link 從 ~30 條長到 217 條(平均每檔 4 條)。
2. 重寫 MEMORY.md 成 cluster 分群
舊版按 4 大類(feedback / reference / project / debugging)分,太籠統。新版按主題分 9 個 cluster:程式碼品質、前端 / UI、MemPalace 記憶宮殿、行為規範、Chrome / MCP 自動化、開發環境、Project 部落格、Project 其他、Reference 工具。每個 cluster 開頭一句話寫共同主題。索引從一份目錄變成一張地圖。
3. 在 CLAUDE.md 加「auto-memory 寫入 SOP」
這是真正治本的一步。在 CLAUDE.md 加一段程序性規則,寫 memory 前必跑四步:
| Step | 動作 |
|---|---|
| 1 | ls ~/.claude/memory/{feedback,reference,project}_*.md 找既有檔 — 同主題擴充,不開新檔 |
| 2 | 判全局 vs 專案級:跨專案規範 → 全局;單一專案細節 → 專案級 |
| 3 | 寫完必加 ## 相關 區塊,至少一條 [[name]] |
| 4 | 更新 MEMORY.md 索引 |
## 相關 / 該全局存到專案級 / MEMORY.md 跟實際檔不同步 — 看到自己犯這四項立刻糾正,不要等我罵。
關鍵不是清單寫了什麼,是把它從「描述性」改成「程序性」。Step 1、2、3、4 是動作,不是觀念。
🌌 從花朵變星雲
整理完之後,我請 Bob 在 Obsidian 重新整理 graph(會掃整個 vault 重建連線)。打開新的 Graph View:
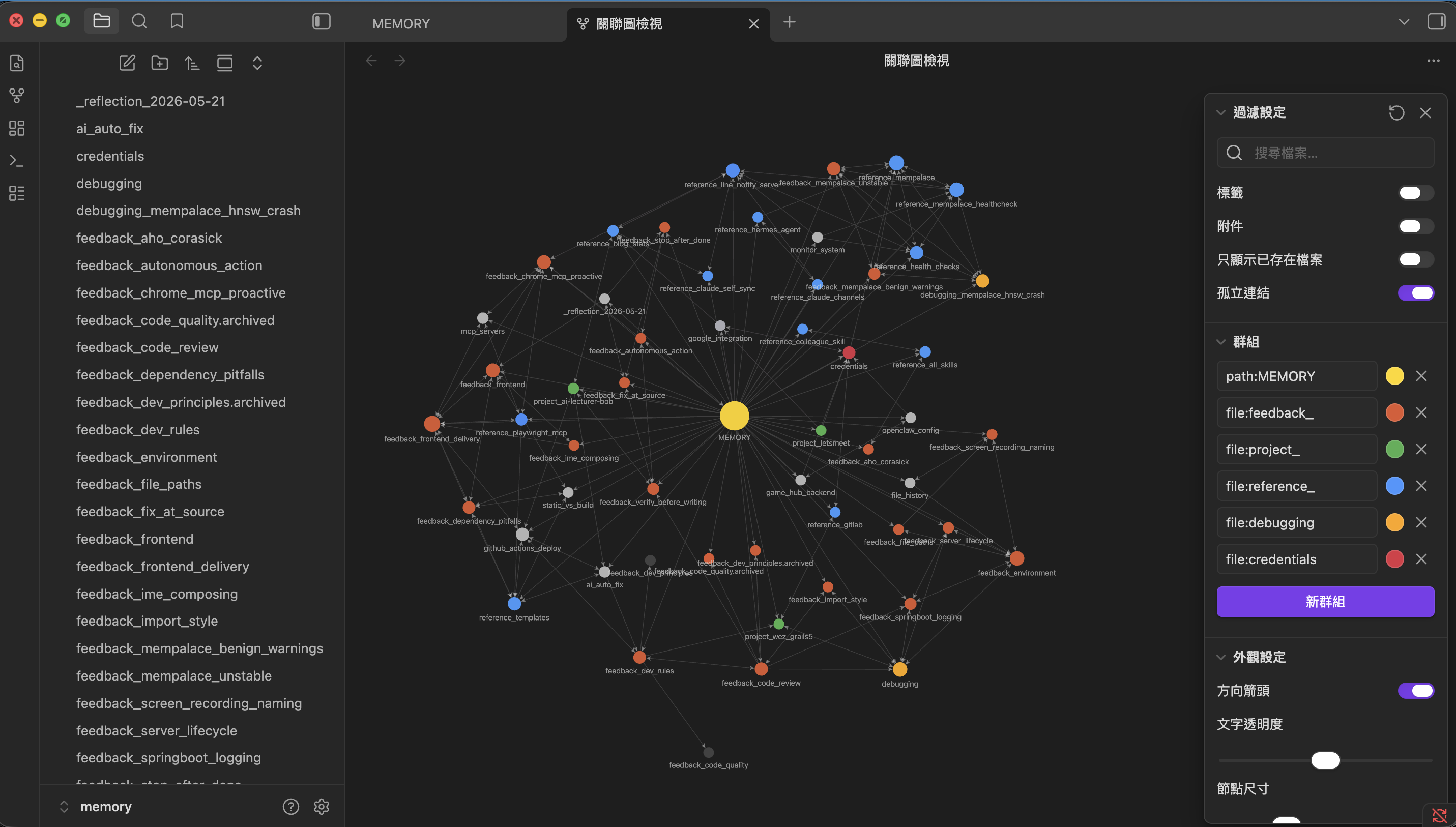
差別:
| 整理前(花朵狀) | 整理後(星雲狀) | |
|---|---|---|
| 中心節點 | MEMORY.md 一個大圓,所有節點向心連 | MEMORY.md 退到一個 cluster 的中心,不再壟斷 |
| 顏色分群 | 全部同色 | 按 file:feedback / file:reference / file:project / file:debugging / file:credentials 染色 |
| 內部連線 | 幾乎沒有 | cluster 內節點互相連、cluster 之間有橋接 |
| 視覺意義 | 目錄 | 網路 |
我之前不知道 memory 長歪,因為我每次只看一個檔。Obsidian Graph 把整個 vault 攤平在同一張圖上 — 不健康的結構是藏不住的。
🎯 這件事真正的教訓
我以為這篇文章是在講「怎麼整理 Claude memory」。寫到最後我發現,真正的教訓不是技術操作,是寫 prompt 跟訓練同事是一樣的事。
你跟新進工程師說:「寫文件前先檢查有沒有重複的。」 — 他會點頭,然後過兩週你發現他開了第三個同主題的 Confluence 頁面。
但你跟他說:「寫文件前先跑 grep -ri <主題> docs/,有結果就 append 進去、沒結果才開新檔。」 — 這條會被執行。
LLM 也一樣。描述性的「應該」永遠輸給程序性的「先做 A,再做 B」。
我下次再覺得 Claude「不夠聰明」之前,我會先問自己:這條規則我給的是描述還是程序?
如果是描述,問題不在 Claude,問題在我。
❓ 常見問題
Claude Code memory 跟 CLAUDE.md 有什麼不一樣?
CLAUDE.md 是你寫給 Claude 的家規,每次 session 全文載入(社群建議控制在 80-120 行)。auto memory 是 Claude 自己抄的筆記,放在 ~/.claude/memory/*.md,需要時 Claude 才會去讀對應檔。兩個搭配用:CLAUDE.md 放紀律跟總綱,memory 放細節跟踩坑。
我的 memory 也很亂,要全部砍掉重來嗎?
不用。先用 Obsidian 開 ~/.claude/memory/ 看 Graph View — 如果是「花朵狀」(所有檔只連中心),代表結構不好但內容可能還可救。先做兩件事:(1) 把同主題的合併,內容好的留下、重複的改 .archived.md 後綴 (2) 每個檔結尾加 ## 相關 區塊。光做這兩件事 graph 就會大幅改善。
怎麼判斷該寫到全局 memory 還是專案級 memory?
跨專案行為規範(寫 code 風格、code review 標準、語氣偏好)→ 全局 ~/.claude/memory/。單一專案的細節(專案路徑、DB 連線、特定 bug 踩坑)→ 專案級 ~/.claude/projects/。不確定的時候優先寫全局,以後可以從專案級補對應 link。
為什麼 Obsidian 比直接看資料夾更有用?
資料夾只能告訴你「有什麼檔」,Graph View 告訴你「檔跟檔之間有沒有關係」。memory 系統的價值來自關係(Claude 透過一個檔找到下一個檔),不是來自檔案數量。資料夾 50 個檔 = 看起來很多;Graph 50 個節點沒連線 = 馬上看出問題。
整理一次要花多久?
我這次 51 個全局檔 + 25 個專案級檔,從反思到 commit 完,大約 3 小時。最花時間的不是合併,是寫 reflection 找根因。如果你 memory 不到 20 個檔,可能 1 小時內搞定。但整理只是治標,改 CLAUDE.md 加 SOP 才是治本,不然 3 個月後又會長回花朵。
🔗 延伸資源
- How Claude remembers your project — 官方 memory 文件
- The Complete Guide to CLAUDE.md (Medium, 2026/05) — CLAUDE.md 80-120 行原則的原始出處
- Obsidian Graph View 官方說明 — 雙向 wikilink 是怎麼運作的
- 系列下一篇:Memory 治理 EP2|為什麼 AI 記不住你寫的規則 — 拆「描述性 vs 程序性」規則設計,搭配實際 CLAUDE.md before/after diff
- 系列下一篇:Memory 治理 EP3|用 Obsidian 看你的 AI 大腦 — Obsidian vault 配 Claude memory 的設定步驟,健診 SOP
📅 明天(2026-05-22)會發:Memory 治理 EP2|為什麼 AI 記不住你寫的規則
拆「描述性」跟「程序性」兩種規則寫法,看 CLAUDE.md 加 4 步 SOP 前後差別,以及怎麼判斷一條規則 LLM 會不會跟。
不怕死,只怕不過癮。